논문에 쓸 수 있는 수준의 Figure 만들기 (R/Python)
논문 투고용 Figure를 R과 Python으로 만들면서 겪은 시행착오. 저널 요구사항 맞추기, DPI, 폰트, 색상 선택까지 실전 팁을 정리합니다.
"Figure 다시 만들어와" — 교수님의 그 한마디
분석은 잘 끝났는데, 논문에 넣을 figure를 만들어서 교수님께 보여드렸더니 돌아온 말: "이거 발표 자료야, 논문이야?" 그때 처음 알았다. 분석 결과를 시각화하는 것과 논문에 출판할 수 있는 수준의 figure를 만드는 것은 완전히 다른 기술이라는 걸.
R에서 plot() 한 줄로 뚝딱 나오는 그래프와, Nature에 실리는 figure 사이에는 넘어야 할 산이 여러 개 있다. 이 글은 그 산들을 넘으면서 쌓은 삽질의 기록이다.
저널이 원하는 건 뭔가
논문 figure에는 엄격한 규격이 있다. 처음에 이걸 몰라서 투고 후 reject 당한 건 아니지만, revision에서 figure 수정만 세 번 했다.
주요 저널의 공통 요구사항:
- 해상도: 최소 300 DPI (line art는 600-1200 DPI)
- 파일 형식: TIFF, EPS, PDF (PNG는 대부분 비추)
- 크기: single column (약 85mm) 또는 double column (약 170mm)
- 폰트: Arial, Helvetica, Times New Roman (크기 6-12pt)
- 색상: CMYK 권장 (일부 저널), 색맹 고려
# ggplot2에서 논문용으로 저장하기
ggsave("figure1.tiff",
plot = p,
width = 170, height = 120, units = "mm",
dpi = 300,
compression = "lzw")
# PDF도 많이 쓴다 (벡터라서 확대해도 깨지지 않음)
ggsave("figure1.pdf",
plot = p,
width = 170, height = 120, units = "mm")
DPI 삽질기
처음에는 DPI가 뭔지도 몰랐다. R의 기본 png() 장치는 72 DPI로 저장하는데, 이걸 그대로 투고했더니 리뷰어한테 "figure가 흐릿하다"는 코멘트를 받았다. 화면에서는 잘 보였는데, 인쇄하면 픽셀이 보이는 거였다.
# 이렇게 하면 안 된다 (기본 72 DPI)
png("figure.png")
plot(data)
dev.off()
# 이렇게 해야 한다
png("figure.png", width = 170, height = 120, units = "mm", res = 300)
plot(data)
dev.off()
Python에서도 마찬가지:
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(6.7, 4.7)) # inches
# ... 그래프 그리기 ...
fig.savefig('figure1.tiff', dpi=300, bbox_inches='tight')
ggplot2 — 논문 figure의 사실상 표준
R에서 논문 figure를 만든다면 ggplot2가 거의 필수다. 처음에는 base R의 plot()으로 다 하려 했는데, 한계를 금방 느꼈다. 패널을 나누고, 범례를 조절하고, 테마를 통일하는 게 base R로는 너무 번거롭다.
library(ggplot2)
library(patchwork) # multi-panel figure의 구원자
# 논문용 테마 설정 — 이거 한 번 만들어두면 계속 쓴다
theme_publication <- theme_classic() +
theme(
text = element_text(family = "Arial", size = 10),
axis.title = element_text(size = 11),
axis.text = element_text(size = 9, color = "black"),
legend.title = element_text(size = 10),
legend.text = element_text(size = 9),
legend.position = "bottom",
strip.text = element_text(size = 10, face = "bold"),
panel.grid = element_blank(),
axis.line = element_line(size = 0.5),
axis.ticks = element_line(size = 0.5)
)
# Volcano plot 예시
p_volcano <- ggplot(de_results, aes(x = log2FC, y = -log10(padj))) +
geom_point(aes(color = significance), size = 0.8, alpha = 0.6) +
scale_color_manual(values = c("gray60", "#E41A1C", "#377EB8")) +
geom_hline(yintercept = -log10(0.05), linetype = "dashed", color = "gray40") +
geom_vline(xintercept = c(-1, 1), linetype = "dashed", color = "gray40") +
labs(x = "log2(Fold Change)", y = "-log10(adjusted p-value)") +
theme_publication
# Heatmap
p_heatmap <- # ... ComplexHeatmap 사용
# 합치기 — patchwork의 마법
combined <- p_volcano + p_heatmap +
plot_layout(widths = c(1, 1.2)) +
plot_annotation(tag_levels = 'A') # A, B 자동 라벨
ggsave("figure2.pdf", combined, width = 170, height = 80, units = "mm")
patchwork을 발견한 날
multi-panel figure를 만들 때 gridExtra::grid.arrange()를 쓰고 있었는데, 패널 크기 조절이 너무 귀찮았다. 그러다 patchwork를 발견한 날, 진심으로 감동했다. p1 + p2만 하면 두 그래프가 나란히 붙고, p1 / p2하면 위아래로 쌓인다. plot_annotation(tag_levels = 'A')하면 A, B, C 라벨까지 자동으로.
Python — matplotlib + seaborn
Python 유저라면 matplotlib이 기본이고, seaborn으로 통계 시각화를 하는 게 일반적이다. 다만 matplotlib의 기본 스타일은 논문용으로는 좀... 못생겼다.
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib as mpl
# 논문용 스타일 설정
mpl.rcParams.update({
'font.family': 'Arial',
'font.size': 10,
'axes.labelsize': 11,
'axes.titlesize': 11,
'xtick.labelsize': 9,
'ytick.labelsize': 9,
'legend.fontsize': 9,
'axes.linewidth': 0.8,
'xtick.major.width': 0.8,
'ytick.major.width': 0.8,
'figure.dpi': 300,
'savefig.dpi': 300,
'savefig.bbox': 'tight',
})
# Violin plot + strip plot 조합
fig, ax = plt.subplots(figsize=(3.5, 3))
sns.violinplot(data=df, x='group', y='expression',
palette=['#E41A1C', '#377EB8', '#4DAF4A'],
inner=None, alpha=0.3, ax=ax)
sns.stripplot(data=df, x='group', y='expression',
palette=['#E41A1C', '#377EB8', '#4DAF4A'],
size=3, alpha=0.7, jitter=True, ax=ax)
ax.set_xlabel('Condition')
ax.set_ylabel('Expression (TPM)')
sns.despine()
fig.savefig('figure3.pdf')
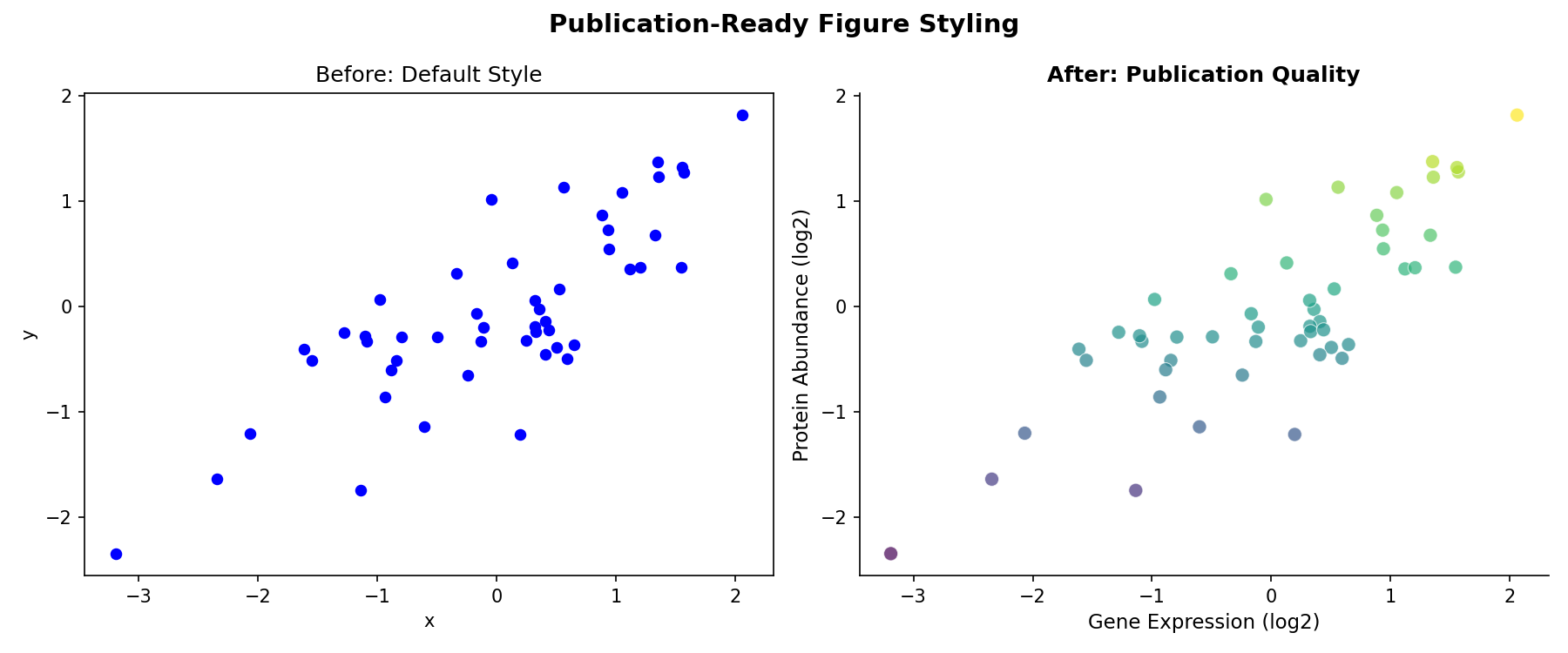
색상 선택 — 예쁜 것보다 중요한 것
처음에는 빨강-초록 조합을 많이 썼다. heatmap도 red-green, volcano plot도 red-green. 리뷰어한테 **"이 figure는 색맹인 독자가 구분할 수 없다"**는 코멘트를 받고 충격받았다.
남성의 약 8%가 적녹색맹이다. 과학 커뮤니티에서는 colorblind-friendly palette를 쓰는 게 이제 거의 필수다.
# 색맹 친화적 팔레트
# viridis 계열 — 연속형 데이터에 최고
scale_fill_viridis_c()
# RColorBrewer — 범주형 데이터
scale_color_brewer(palette = "Set2")
# 직접 지정할 때 — Wong palette (Nature Methods 추천)
wong_colors <- c("#E69F00", "#56B4E9", "#009E73",
"#F0E442", "#0072B2", "#D55E00", "#CC79A7")
heatmap의 색상도 red-green 대신 blue-white-red 또는 viridis를 쓰게 됐다. 처음에는 "뭐 이렇게까지" 싶었는데, 실제로 colorblind simulator로 내 figure를 확인해봤더니 red-green 조합은 정말 구분이 안 됐다.
ComplexHeatmap — heatmap의 끝판왕
논문에서 heatmap이 필요하면 ComplexHeatmap을 쓴다. Bioconductor에서 설치할 수 있고, 저자 Zuguang Gu가 정말 열정적으로 관리하는 패키지다.
library(ComplexHeatmap)
library(circlize)
# 색상 매핑
col_fun <- colorRamp2(c(-2, 0, 2), c("#2166AC", "white", "#B2182B"))
# annotation 추가
ha_top <- HeatmapAnnotation(
condition = sample_info$condition,
batch = sample_info$batch,
col = list(
condition = c("Control" = "#377EB8", "Treatment" = "#E41A1C"),
batch = c("A" = "#66C2A5", "B" = "#FC8D62")
)
)
Heatmap(expression_matrix,
col = col_fun,
top_annotation = ha_top,
show_row_names = FALSE,
column_title = "Top 50 DE Genes",
name = "Z-score",
clustering_distance_rows = "euclidean",
clustering_method_rows = "ward.D2")
pheatmap도 간편하지만, annotation을 세밀하게 조절하려면 ComplexHeatmap이 압도적이다. 처음에는 학습 곡선이 있지만, 한 번 익히면 어떤 heatmap이든 만들 수 있다.
실전 팁 모음
1. 폰트 임베딩
PDF로 저장할 때 폰트가 임베딩 안 되면, 다른 컴퓨터에서 열었을 때 글자가 깨진다. 투고 시스템에서도 문제가 생길 수 있다.
# R에서 폰트 임베딩
library(extrafont)
loadfonts()
# 또는 cairo_pdf() 사용
cairo_pdf("figure.pdf", width = 6.7, height = 4.7)
2. 패널 라벨 (A, B, C)
Illustrator에서 수동으로 A, B, C를 붙이는 건 수정할 때마다 다시 해야 하니까 비효율적이다. 코드에서 자동으로 붙이자.
# patchwork
combined + plot_annotation(tag_levels = 'A',
tag_prefix = '',
tag_suffix = '')
3. 그래프를 다시 만들어야 할 때를 대비하라
리뷰어가 "색상 바꿔라", "축 범위 바꿔라", "이 샘플 빼고 다시 그려라" 하는 건 일상이다. 그래서 모든 figure는 스크립트로 만들어야 한다. Illustrator에서 수동으로 꾸민 figure는 수정 요청이 올 때마다 처음부터 다시 해야 한다.
figures/
├── figure1.R # Figure 1 생성 스크립트
├── figure2.R # Figure 2 생성 스크립트
├── figure_theme.R # 공통 테마
├── output/
│ ├── figure1.pdf
│ └── figure2.pdf
└── Makefile # make figure1 으로 재생성
이 구조를 처음부터 잡아놨으면 좋았을 텐데, revision 3회차에서야 이 구조로 바꿨다. BRIC(bric.pe.kr)의 연구 관련 커뮤니티에서도 figure 관리 팁이 자주 공유되니 참고하면 좋다.
R vs Python — figure는 어디서?
둘 다 써본 결론:
- 정적 figure (논문용): ggplot2 (R)이 더 편하다.
theme()시스템이 강력하고, Bioconductor 시각화 패키지와의 연계가 자연스럽다. - 인터랙티브 figure (발표용): plotly (Python/R) 또는 bokeh (Python).
- heatmap: ComplexHeatmap (R)이 압도적. Python의 seaborn.clustermap은 커스터마이징 한계가 있다.
하지만 분석이 Python이면 figure도 Python으로 만드는 게 워크플로우가 깔끔하다. 데이터를 R로 옮기는 과정에서 실수할 여지를 줄이는 것도 중요하다.
데이터 시각화와 AI의 결합이 점점 흥미로워지고 있다. BioAI Market(sysofti.com)에서 AI 기반 시각화 도구의 트렌드를 확인할 수 있고, KBRAIN MAP(kbrain-map.org)에서도 AI 연구 시각화 관련 리소스를 찾을 수 있다.
마무리
논문 figure 만들기는 "그래프 그리기"가 아니라 시각 커뮤니케이션이다. 독자가 figure만 보고도 메시지를 이해할 수 있어야 한다. DPI, 폰트, 색상, 레이아웃... 사소해 보이는 것들이 모여서 논문의 품질을 결정한다.
처음에는 교수님한테 "다시 해와"를 수십 번 듣고 좌절했지만, 지금은 figure 만드는 게 분석 과정에서 가장 재미있는 부분이 됐다. 삽질 끝에 예쁜 figure가 나왔을 때의 만족감은 특별하다.
관련 리소스:
관련 글
Can an LLM Run an RNA-seq Analysis on Its Own? Building ARIA, a Decision-Aware Transcriptome Framework
6월 2일 · 6 min read
BioinformaticsA MOGONET-Style Multi-Omics Biomarker Pipeline: Why a Near-Random Graph Net Still Earns Its Place
6월 1일 · 10 min read
BioinformaticsGO and Pathway Enrichment Analysis: A Complete Practical Guide (clusterProfiler, fgsea, MSigDB)
5월 4일 · 13 min read
BioinformaticsNGS 데이터 전처리 — FastQC에서 멈추면 안되는 이유
2월 25일 · 10 min read